
머신러닝 알고리즘은 지도 학습, 비지도 학습, 강화 학습 등으로 분류됩니다. 이들을 분류하는 기준은 학습 데이터의 특징과 사용방법입니다.
# 지도 학습
먼저 지도 학습은 인풋과 아웃풋의 정답(label)이 모두 주어진 상태에서 학습하는 방법입니다. 컴퓨터가 입력과 출력과의 관계를 학습하여 새로운 입력에 대한 결과를 예측합니다. 지도 학습으로는 분류와 회귀분석 문제를 다룰 수 있습니다.

분류의 대표적인 예시로 개와 고양이 사진을 구분하는 문제가 있습니다. 정확하게 개, 또는 고양이 레이블이 주어진 사진 데이터셋이 훈련에 사용됩니다. 이 데이터셋으로 개와 고양이를 분류하는 알고리즘을 만드는 것이 머신러닝 학습의 목적입니다. 지도 학습을 완료한 모델은 처음 보는 사진을 입력해도 개와 고양이를 구분해낼 수 있습니다.
회귀분석은 입력과 출력이 연속적인 숫자로 주어졌을 때 이들의 함수관계를 학습하는 문제입니다. 이것을 이용하여 새로운 입력에 해당하는 출력 값을 추론할 수 있습니다. 시간에 따라 변화하는 시계열 데이터로 미래를 예측하는 것도 가능합니다. 주식 가격, 주택 가격을 예측하는 문제를 예로 들 수 있겠네요. 가장 간단한 회귀분석 문제는 데이터셋을 가장 잘 나타내는 하나의 직선을 찾는 것인데, 이것을 선형 회귀분석이라고 합니다.
# 비지도 학습
비지도 학습은 앞서 살펴본 지도 학습과 달리 정답(label)이 주어지지 않은 상태에서 데이터의 특성을 파악하는 방법입니다. 비지도 학습으로 배우는 것은 데이터셋에 숨겨진 패턴입니다. 비지도 학습으로는 군집화(Clustering) 문제를 다룰 수 있습니다. K-mean clustering은 대표적인 비지도 학습 모델로, 주어진 데이터를 K개의 군집으로 묶는 간단한 알고리즘입니다.
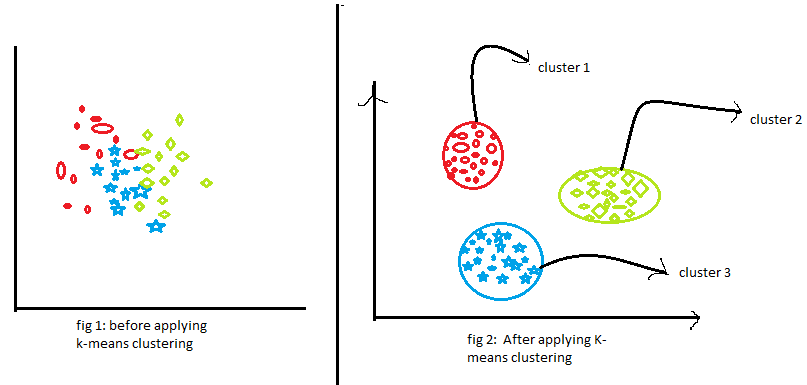
이처럼 군집화는 훈련 데이터셋에서 서로 유사한 것들을 스스로 묶어 군집을 형성하는 작업입니다. 군집화 알고리즘들의 기본 아이디어는 같은 군집에 속한 데이터와의 거리는 최소로 줄이고, 다른 군집에 속한 데이터와의 거리는 최대로 늘리기 위하여 군집의 소속을 바꿔가면서 최적의 구성을 찾는 것입니다.
군집화를 위해서는 유사한 정도의 기준을 미리 정해 두어야 합니다. 이때 유사도는 데이터 간 '거리'를 가지고 판단할 수 있습니다. 이렇게 데이터 간 유사도를 측정하기 위해 사용하는 거리의 개념은 유클리드 거리(Euclidean distance), 맨해튼 거리 (Manhattan Distance) 등을 포함하여 여러 가지가 있습니다.
# 강화 학습
강화 학습은 바람직한 행동 패턴을 학습하는 알고리즘입니다.

강화 학습의 환경은 에이전트가 처할 수 있는 상태의 변화와 보상으로 정의됩니다. 보상은 현재 행동에 의해 즉시 얻게 되는 이득입니다. 이런 환경에서 에이전트는 누적되는 보상이 최대가 되도록 하는 행동 패턴을 학습해야 합니다. 강화 학습은 입력 lable이 주어지지 않는다는 점에서 지도 학습과 다르고, 상황 종료 시에는 보상을 통해 정답 lable과 비슷한 효과를 내기 때문에 비지도 학습과도 차이가 있습니다.
지능적인 에이전트는 시작부터 종료 시점까지 누적되는 보상을 최대화하는 행동의 순서, 즉 패턴을 배워야 합니다. 에이전트의 바람직한 행동은 매 순간마다의 경우의 수 중에서 누적 보상의 기댓값이 가장 큰 것을 선택하는 것입니다. 강화 학습 모델은 자율주행차의 조정, 로봇 제어 등의 문제에서 사람을 능가하는 성과를 보여주고 있습니다.
지금까지 지도 학습, 비지도 학습, 강화 학습에 대해 살펴보았습니다.
'AI' 카테고리의 다른 글
| Generalization, Normalization, Standardization (0) | 2022.08.12 |
|---|---|
| binary & multinomial (0) | 2022.08.08 |
| 분류(classification), 군집화(clustering), 회귀(regression) (0) | 2022.07.17 |
| Train set - Validation set - Test set (0) | 2022.07.16 |
| 머신러닝(Machine Learning)이란? (0) | 2022.07.16 |




댓글